析合树学习笔记
做题做到了,发现大纲里没有,怕某些阴间人当线段树出出来,随便学学。
可能不是很严谨,姑且看看吧。
1 一些定义
1.1 连续段
对于一个排列 $P$,我们定义它上面的一个区间 $(P, [l, r])$ 为一个 “连续段”,当且仅当它满足 $P_l \sim P_r$ 在值域上是连续的。
或者说对 $P_l \sim P_r$ 中的元素 $\max - \min = r - l$,即极差与区间长度相等。
我们发现,对于两个连续段 $A, B$,其 交、并、差 都是连续段,证明略,可以自行感性理解一下。
1.2 本原段
我们按照上面连续段的定义,不难发现一个排列的连续段数量可以达到 $\mathcal{O}(n^2)$ 级别,难以形成一个优秀的数据结构。
因此我们考虑选取一些具有代表性的连续段,于是我们引入了 “本原段” 的概念。
我们一个连续段是一个 “本原段”(或者叫本原连续段),当且仅当不存在另外一个连续段与其 部分相交。
根据其定义,我们不难发现两个本原段只可能是 相离或包含 的关系。
2 一些基本信息
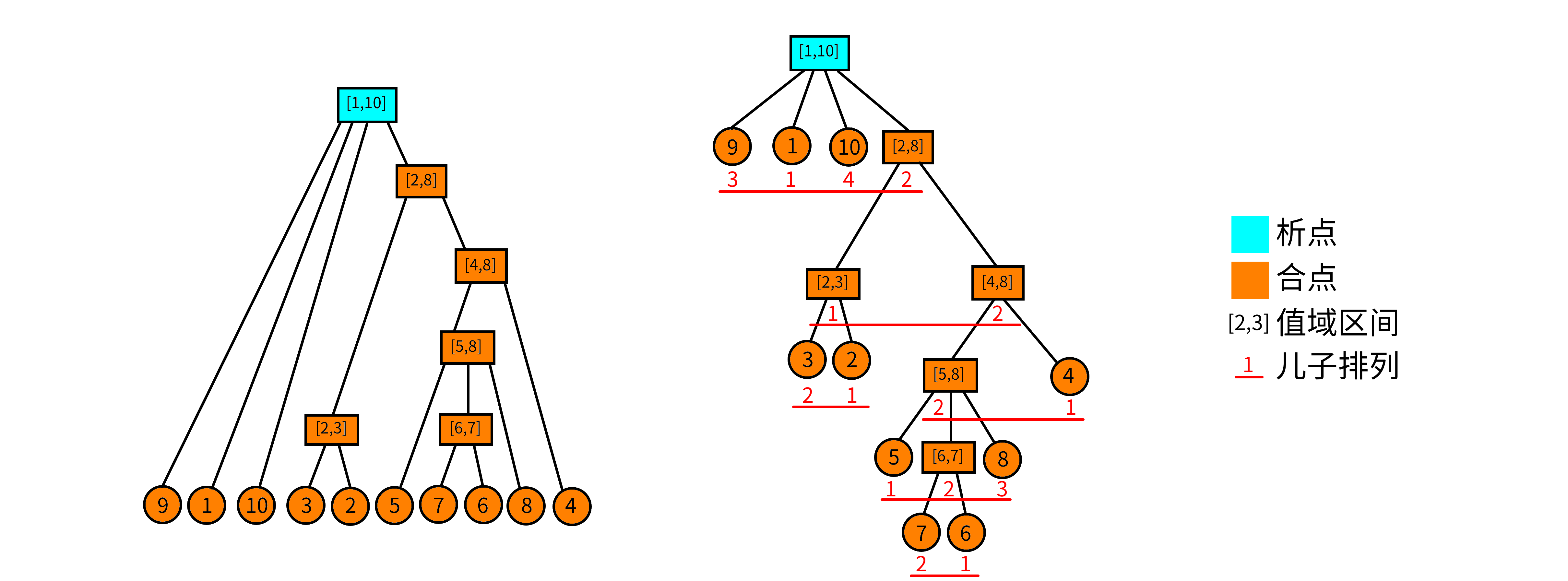
2.1 析合树结构
我们考虑把所有本原段建成一个和线段树类似的树形结构,称为 “析合树”,每一个本原段对应结点的所有儿子结点的集合就是构成它的所有 极大本原段 对应结点的集合。
因此不难发现,一个非叶子结点至少有两个儿子,因此结点个数的上界是 $2n-1$。
考虑每一个本原段对应一个值域上的区间,我们定义一个结点的 值域区间 为它对应的这个区间。
然后对于一个非叶子结点,我们把它所有的儿子按原序列上的顺序加到一个序列中,称之为这个结点的 “儿子序列”。
再把 “儿子序列” 按 “值域区间左端点从小到大” 离散化,得到一个排列,我们称它为这个结点的 “儿子排列”。
然后我们终于可以引入 “析合” 的概念了,我们把所有点分为两类:
- 合点:这个结点的儿子排列单调(递增或递减),特殊的,一个叶子结点也是一个合点。
- 析点:若一个点不是合点就是析点。
下面这幅 oi-wiki 上的图片应该可以很直观地阐释一个析合树的结构:
2.2 一些性质
析点和合点这么分显然是有性质的:
- 合点:儿子序列中的每一个严格子区间都是一个连续段。
- 析点:儿子序列中的每一个长度大于 $1$ 的严格子区间都不是一个连续段。
合点的性质很显然,析点这个就有点难以理解了。
我们可以考虑这个结点儿子序列中的每一个长度大于 $1$ 的严格子区间,若其中存在一个连续段,那么必有另一个与其相交的严格子区间也是一个连续段,否则它会成为一个本原连续段而违反了定义。
而这样归纳证明下去,会导致这个结点儿子序列中每一个长度大于 $1$ 的严格子区间都形成一个连续段,这会使它成为一个合点。
因此儿子序列中的每一个长度大于 $1$ 的严格子区间都不是一个连续段。
也因此,一个析点至少有 $4$ 个儿子(两个或三个都会合并),不过这性质没啥用。
而且很显然,一个连续段要么就是析合树上的一个结点,此时它是一个本原段;要么可以被某个结点的儿子序列表示出来,而不是像线段树一样由多个结点表示,这个考虑本原段和连续段的性质就能理解了,详细证明略。
另外,注意到如果我们只按性质来划分析合的话,那么一个叶子结点既可以是析点也可以是合点(虽然定义上是合点),因此也许可以方便实现,减少分讨。
3 析合树的构造
LCA 的课件里面给出了一个 $\mathcal{O}(n)$ 的建树方法,个人觉得在 OI 中用处应该不大,所以暂时不写。
这里只提供一种比较容易使用的 $\mathcal{O}(n\log n)$ 做法。
3.1 增量法
顾名思义,我们假设我们已经构造出了一个原序列中前 $k-1$ 个元素的析合森林,考虑要插入第 $k$ 个结点时我们要怎么做。
我们可以进行如下分讨:
- 若待插入结点可以成为栈顶结点的儿子,那么弹出栈顶,并把栈顶结点变为待插入结点继续这一过程。这里显然要求栈顶是一个有至少两个儿子的合点。
- 若待插入结点可以与栈顶点合并成一个新合点那么合并,然后弹出栈顶并把合并后的结点变为待插入结点继续这一过程。
- 创建一个析点并把栈顶尽可能少的元素与待插入结点作为这个新析点的儿子,把对应的栈顶全部弹出然后把新析点变为待插入结点继续这一过程。
- 若上面三步都做不到,则将当前的待插入结点入栈然后结束这一过程。
首先不难发现这么做一定可以构造出前 $k$ 位的一个析合森林。
构造出的是森林是因为前 $k$ 位值域不一定连续,因此生成的树也不一定连通
然后要说明它一定是合法的析合森林,这边给出一个比较口胡的解释:
- 首先只要每一个的析或者合显然都是确定的,那么我们只需要每一个结点与一个本原连续段对应即可。
- 我们考虑进行完这一通操作之后每一个点确实都是本原的并且涵盖所有本原连续段,原因在于新加入的结点显然只会影响到原栈的一个后缀,而每一个后缀的可合并性我们都已经判断过了。
然后注意到显然每一个结点只会进出栈一次,因此要是每一步操作都能快速实现我们就得到了一个不错的构造方法。
注意到 $1, 2$ 两个操作都是均摊 $\mathcal{O}(n)$ 的,问题就在于第三步这个 “尽可能少” 怎么快速处理。
我们考虑一个比较直观的实现。
我们定义 $L_i$ 表示以 $i$ 为右端点,序列上最左的一个左端点使得 $(P, [L_i,i])$ 是个连续段。
考虑我们这样就可以暴力处理栈顶,不难发现处理到 $L_i$ 之前不会出现 $4$ 这一步,因此每一个栈顶都只会被访问到一次,然后就会被弹出。
因此均摊还是 $\mathcal{O}(n)$ 次的,那么我们考虑这个东西怎么求。
我们考虑一个连续段的性质,注意到它有一个充要条件是极差与区间长度相等。
注意到一个排列的性质:
而我们需要的是:
因此我们考虑维护一个 $(\max - \min) - (r - l)$ 的最小值,这样就可以方便地用线段树找 $0$ 来实现查找对应结点的任务。
$\max, \min$ 的维护可以使用单调栈,当然也可以直接线段树上二分然后暴力推平。
移动右端点然后维护 $r-l$ 是个传统艺能,实现精细的话甚至不需要全局加。
放张 oi-wiki 上的长图,虽然我觉得不一定有助于理解:
显示长图

4 例题
CF526F Pudding Monsters
给你一个长度为 $n$ 的排列,问你这个排列中连续段的数量。
$n \le 3\times 10^5$
显示解法
注意到所有连续段都能被析合树上的某个结点或某个合点儿子序列中的一段区间表示出来。
因此对于每一个析点,其贡献就是 $1$,对于每一个合点,假设它有 $k$ 个儿子,其贡献就是 $\binom{k}{2}+1$。
复杂度就是建树复杂度,$\mathcal{O}(n\log n)$ 或 $\mathcal{O}(n)$。
P4747 [CERC2017]Intrinsic Interval
给你一个长度为 $n$ 的排列,有 $q$ 次询问,每次询问一段区间 $[l, r]$,问你完全包含这段区间的最短连续段。
$n, q \le 10^5$
显示解法
首先包含区间 $[l, r]$ 其实就是同时包含 $l, r$ 两个点。
考虑求出这两个点的 LCA,然后针对 LCA 是析点还是合点讨论:
- 若是析点,显然包含 $[l, r]$ 的最短连续段就是这个点对应的连续段。
- 若是合点,则是其儿子序列中的一段子区间,二分或者 $k$ 级祖先都能求出对应的左右端点。
复杂度 $\mathcal{O}(n\log n)$。
CF997E Good Subsegments
给你一个长度为 $n$ 的排列,有 $q$ 次询问,每次询问一段区间 $[l, r]$,问你有多少连续段被这段区间完全包含。
$n, q \le 1.2\times 10^5$
显示解法
还是考虑求出这两个点的 LCA,然后考虑找出这两个点的对应在 LCA 的儿子序列中的那两个点。
注意到这两个点所包括的一段区间中的点子树内所有连续段都合法。
然后又注意到若这个点是合点,则还应该多计算 LCA 儿子序列的一些子区间组成的一些连续段。
然后其实就很方便地做完了。
复杂度 $\mathcal{O}(n\log n)$,注意到这是个在线算法。
5 代码实现
实现的是 P4747,为了方便理解增加了一些注释,并删除了快读,因此直接提交这份代码无法通过,不过不影响阅读。
基本上参考了 oi-wiki 上的实现,不过这份应该更为容易实现一些。
展开代码
#include <assert.h>
#include <cstdio>
#include <cstring>
#include <algorithm>
#define debug(...) fprintf(stderr, __VA_ARGS__)
#define rep(i,s,t) for(int i=(s),i##END=(t);i<=i##END;++i)
#define per(i,t,s) for(int i=(t),i##END=(s);i>=i##END;--i)
#define REP(i,s,t) for(int i=(s),i##END=(t);i<i##END;++i)
#define PER(i,t,s) for(int i=(t),i##END=(s);i>i##END;--i)
template <typename T>
inline T mn(const T x, const T y) { return x < y ? x : y; }
template <typename T>
inline T mx(const T x, const T y) { return x > y ? x : y; }
typedef long long LL;
/* My Code begins here */
const int MAXN = 1e5 + 5;
int n, a[MAXN];
#include <vector>
struct NODE {
int l, r; bool type; // 每一个结点的值域区间与类型(析/合)
NODE (int l = 0, int r = 0, bool type = 0) : l(l), r(r), type(type) {}
}t[MAXN << 1]; // 注意点数是 2n-1,因此要开两倍空间
// 每一个结点的儿子序列,其实也就是出边
std::vector < int > d[MAXN << 1];
// 这里对于每一个结点要多维护一个 M 表示其最右侧的一个儿子的左端点,方便判断当前点是否可以成为栈顶的新儿子,详细的可以看 build() 函数
int tot = 0, M[MAXN << 1];
struct Segtree {
int t[MAXN << 2], tag[MAXN << 2];
inline void pushup(int rt) { t[rt] = mn(t[rt << 1], t[rt << 1 | 1]); }
inline void update(int rt, int z) { t[rt] += z; tag[rt] += z; }
inline void pushdown(int rt) {
if(tag[rt]) {
update(rt << 1, tag[rt]);
update(rt << 1 | 1, tag[rt]);
tag[rt] = 0;
}
}
#define LSON rt << 1, l, mid
#define RSON rt << 1 | 1, mid + 1, r
void build(int rt, int l, int r) {
tag[rt] = 0; if(l == r) return t[rt] = l, void();
int mid = (l + r) >> 1;
build(LSON); build(RSON);
pushup(rt);
}
int query(int rt, int l, int r) { // 找出最左的一个 0
if(l == r) return l;
int mid = (l + r) >> 1; pushdown(rt);
return t[rt << 1]? query(RSON) : query(LSON);
}
int ask(int rt, int l, int r, int x) { // 单点查询,若是 0 则说明可以形成连续段
if(l == r) return t[rt];
int mid = (l + r) >> 1; pushdown(rt);
return x <= mid? ask(LSON, x) : ask(RSON, x);
}
void modify(int rt, int l, int r, int x, int y, int z) { // 区间修改
if(x <= l && r <= y) return update(rt, z);
int mid = (l + r) >> 1; pushdown(rt);
if(x <= mid) modify(LSON, x, y, z);
if(y > mid) modify(RSON, x, y, z);
pushup(rt);
}
}sgt;
int stk1[MAXN], tp1, stk2[MAXN], tp2, s[MAXN], tp;
int id[MAXN], root;
// 树剖求 LCA
int dep[MAXN << 1], tt[MAXN << 1], fa[MAXN << 1], sz[MAXN << 1], son[MAXN << 1];
void dfs(int x) {
sz[x] = 1; for (auto v : d[x]) {
fa[v] = x; dep[v] = dep[x] + 1;
dfs(v); sz[x] += sz[v];
if(sz[v] > sz[son[x]]) son[x] = v;
}
}
void dfs2(int x, int lt) {
tt[x] = lt; if(son[x]) dfs2(son[x], lt);
for (auto v : d[x]) if(v != son[x]) dfs2(v, v);
}
inline int LCA(int x, int y) { // 树剖求 LCA
while(tt[x] ^ tt[y]) {
if(dep[tt[x]] < dep[tt[y]]) std::swap(x, y);
x = fa[tt[x]];
}
return dep[x] > dep[y]? y : x;
}
inline void build() {
sgt.build(1, 1, n); // 建树,初值为 l
rep(i, 1, n) {
sgt.update(1, -1); // 右端点移动时全局减
// 单调栈维护 max/min 常数似乎小一些,注意弹栈时要撤销贡献
while(tp1 && a[i] <= a[stk1[tp1]]) { sgt.modify(1, 1, n, stk1[tp1 - 1] + 1, stk1[tp1], a[stk1[tp1]]); -- tp1; }
while(tp2 && a[i] >= a[stk2[tp2]]) { sgt.modify(1, 1, n, stk2[tp2 - 1] + 1, stk2[tp2], -a[stk2[tp2]]); -- tp2; }
sgt.modify(1, 1, n, stk1[tp1] + 1, i, -a[i]); stk1[++ tp1] = i;
sgt.modify(1, 1, n, stk2[tp2] + 1, i, a[i]); stk2[++ tp2] = i;
// 建立一个新的待插入结点
t[id[i] = ++ tot] = NODE(i, i, 0);
const int lim = sgt.query(1, 1, n); int u = tot;
while(tp && t[s[tp]].l >= lim) { // 注意这里要反复进行
if(t[s[tp]].type && !sgt.ask(1, 1, n, M[s[tp]])) { // 第一类分讨,看是否能成为儿子
t[s[tp]].r = i; M[s[tp]] = t[u].l; d[s[tp]].push_back(u); u = s[tp --];
} else if(!sgt.ask(1, 1, n, t[s[tp]].l)) { // 第二类分讨,看是否能合并
t[++ tot] = NODE(t[s[tp]].l, i, 1); M[tot] = t[u].l;
d[tot].push_back(s[tp --]); d[tot].push_back(u); u = tot;
} else { // 第三类分讨,尽可能少的结点合并建立析点
d[++ tot].push_back(u);
do { d[tot].push_back(s[tp --]); } while(tp && sgt.ask(1, 1, n, t[s[tp]].l));
t[tot] = NODE(t[s[tp]].l, i, 0);
d[tot].push_back(s[tp --]);
u = tot;
}
}
s[++ tp] = u; // 最后入栈
}
dep[root = s[1]] = 1; dfs(root); dfs2(root, root); // 建析合树
}
signed main() {
cin >> n; rep(i, 1, n) cin >> a[i];
build();
int q; cin >> q; while(q --) {
int l, r; cin >> l >> r; l = id[l]; r = id[r];
const int lca = LCA(l, r);
if(t[lca].type) { // 如果是合点,则在儿子序列中二分
int L = *(-- std::upper_bound(d[lca].begin(), d[lca].end(), l, [](int x, int y) { return t[x].l < t[y].l; }));
int R = *(-- std::upper_bound(d[lca].begin(), d[lca].end(), r, [](int x, int y) { return t[x].l < t[y].l; }));
cout << t[L].l << ' ' << t[R].r << endl;
}
else // 析点则可以直接输出
cout << t[lca].l << ' ' << t[lca].r << endl;
}
}
6 总结
今年 CSP 都已经敢把网络流当最短路考了(虽然正解确实是最短路),那 NOIP 把析合树当线段树考不过分吧。
反正看起来连续段问题都能套个析合树,而且板子其实不算难背,哪怕现场推也不会耗很多时间。
但是考到概率还是不能算大,不过至少比什么分散层叠有用。